╣±ŲŌźšźĪźųźņź╣╚ŠŲ│öüź┘ź¾ź┴źŃĪ╝ĪóTRIPLE-1ż¼AIź│źóż“│½╚»
Ų³╦▄ż╦żŌ├┬Ö┌żĘż┐źšźĪźųźņź╣╚ŠŲ│öüź┘ź¾ź┴źŃĪ╝ż¼AIź┴ź├źūż“║ŅżļżĶż”ż╦ż╩ż├żŲżŁż┐ĪŻ╩ĪŃK▌xż╦╦▄╝ęż“Åøż»źšźĪźųźņź╣╚ŠŲ│öüż╬TRIPLE-1żŽĪó│žØ{żĄż╗żļż│ż╚ż“┴└ż├ż┐AIź┴ź├źūĪųGOKUĪūż“│½╚»├µż└Ī╩┐▐1Ī╦ĪŻ║Ū└Ķ├╝ż╬5nmźūźĒź╗ź╣ż“╗╚ż”AIź┴ź├źūż╦ĮĖ└čż╣żļź│źóż╬│½╚»ż“ż│ż╬ż█ż╔£½żķż½ż╦żĘż┐ĪŻ

┐▐1ĪĪ╣±ŠÅźšźĪźųźņź╣╚ŠŲ│öüź┘ź¾ź┴źŃĪ╝ż¼│½╚»żĘż┐AIź│źóĪĪĮąųZĪ¦TRIPLE-1
AIź┴ź├źūż╦ż╩ż╝5nmż╚żżż”«Ć╚∙║┘▓ĮČ\Įčż¼ØŁ═ūż╩ż╬ż½ĪŻź╦źÕĪ╝źĒź¾źŌźŪźļżŪ╔ĮĖĮżĄżņżļMAC▒ķōQ▀_(d©ó)ż“¾H┐¶Ą═żß╣■żßżņżąĄ═żß╣■żßżļż█ż╔Īó┐═┤ųż╬╦Nż╦ŖZż┼ż▒żļż½żķż└ĪŻ┐═┤ųż╬╦Nż╦żŽĮj(lu©░)╦Nż╦┐¶╝åĖ─ĪóŠ«╦Nż╦żŽ1000▓»Ė─ż╬┐└Ęą║┘╦”Īóż╣ż╩ż’ż┴ź╦źÕĪ╝źĒź¾ż¼żóżļż╚żżż’żņżŲżżżļĪŻżĮżņżķżŽ╚∙Š«ż╩┼┼Ąż┐«ęÄ(gu©®)żŪŠ╩¾ż“┴„£p┐«żĘżŲżżżļĪŻż│ż╬ź╦źÕĪ╝źĒź¾ż“┐┐ō¶ż┐żŌż╬ż¼ź╦źÕĪ╝źķźļź═ź├ź╚ź’Ī╝ź»żŪżóżļĪŻ▓»├▒░╠ż╬ź╦źÕĪ╝źĒź¾ż“ĮĖ└čżĘż┐ż╚żżż”AIź┴ź├źūżŽż▐ż└ż╩żżżŌż╬ż╬Īó┐¶╝åĖ─ż╬ź╦źÕĪ╝źĒź¾ż“ĮĖ└čżĘż┐AI╚ŠŲ│öüövŽ®żŽż╣żŪż╦IBMż¼╗Ņ║ŅżĘżŲżżżļĪŻż┐ż└żĘĪóźŪźĖź┐źļżŪ╔ĮĖĮż╣żļŠņ╣ńż╦źųźĒź├ź»ŲŌż╦ĮĖ└čż╣żļź╦źÕĪ╝źĒź¾┐¶ż¼ź┴ź├źū└▀╝Ŗż╦żĶż├żŲż▐ż┴ż▐ż┴ż╩ż┐żßĪóź┴ź├źū┼÷ż┐żĻż╬ź╦źÕĪ╝źĒź¾┐¶ż╚żżż”╔ĮĖĮżŽżĘż╩żżżĶż”ż└ĪŻ
ź╦źÕĪ╝źķźļź═ź├ź╚ź’Ī╝ź»ż╬źŌźŪźļżŪżŽĪóź╦źÕĪ╝źĒź¾1Ė─żŽĪó¾HŲ■╬üĪ”1Įą╬üż╬źčĪ╝ź╗źūź╚źĒź¾źŌźŪźļżŪĄŁĮ꿥żņżļż│ż╚ż¼¾HżżĪŻŲ■╬üżŽźŪĪ╝ź┐ż╚─_ż▀ż“▓├ż©żŲ▒ķōQż╣żļ(┐▐2)ĪŻź╦źÕĪ╝źĒź¾1Ė─ż╬▒ķōQżŽĪóźŪźĖź┐źļ┼¬ż╦╔ĮĖĮż╣żļż╚ĪóźŪĪ╝ź┐1Ī▀─_ż▀1+źŪĪ╝ź┐2Ī▀─_ż▀2+Ī”Ī”Ī”Ī”+źŪĪ╝ź┐nĪ▀─_ż▀nĪóż╚żżż”┐¶╝░żŪ╔ĮĖĮżĄżņżļĪŻż╣ż╩ż’ż┴└č(²Xż▒ōQ)Ž┬(’BżĘōQ)▒ķōQĪ╩MAC: multiply accumulate calculationĪ╦ż“╣įż├żŲżżżļż│ż╚ż╦┴Ļ┼÷ż╣żļĪŻżŌż┴żĒż¾źóź╩źĒź░┼¬ż╦żŌ¾H┐¶ż╬Ų■╬üźŪĪ╝ź┐ż╦¾H┐¶ż╬─_ż▀ż“▓─╩č°BŃ^żŪ╔Įż╣ż│ż╚żŌżŪżŁżļĪŻ
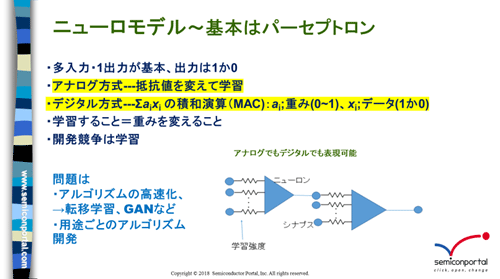
┐▐2ĪĪź╦źÕĪ╝źķźļź═ź├ź╚ź’Ī╝ź»ż╬┼∙▓┴övŽ®ĪĪ╔«Ūv║Ņ└«
Įą╬ü├═żŽ1ż½0ż╚ż╣żļŠņ╣ńż¼¾HżżĪŻ¾H┐¶ż╬Ų■╬ü▒ķōQż“’BżĘ╣ńż’ż╗żŲĮą╬üż╬1ż½0ż“╔ĮĖĮż╣żļż┐żßż╦Īó▒ķōQŗ╩¼żŽź╣źŲź├źū┤ž┐¶Īóż─ż▐żĻź│ź¾źčźņĪ╝ź┐ż╬żĶż”ż╦żĘżŁżż├═ż“╬Ńż©żą0.5ż╦─ĻżßĪóżĮżņ░╩æųż“1Īó░╩▓╝ż“0żŪ╔Įż╣ĪŻŽó¶ö┤ž┐¶żŪ╔Įż’ż╗żąź╣źŲź├źū┤ž┐¶żŽĪóźĘź░źŌźżź╔┤ž┐¶żŪŖZō¶żŪżŁżļĪŻź╦źÕĪ╝źĒź¾ż╬┐¶ż“╗\żõż╗żąĮ∙Ī╣ż╦┐═┤ųż╬Ų¼╦Nż╦ŖZż┼żŁ┘ćżĘżż┼·ż©ż“Ų│ż»ż└żĒż”Īóż╚żżż”„[─ĻżŪź╦źÕĪ╝źĒź¾ż“╣Į└«ż╣żļĪŻ
żĮż│żŪĪó▐kż─ż╬ź╦źÕĪ╝źĒź¾ż½żķ╝Īż╬ź╦źÕĪ╝źĒź¾żžż╚╝ĪĪ╣ż╚ź═ź├ź╚ź’Ī╝ź»ż“╣Į└«ż╣żļĪŻż│żņż“źŪźĖź┐źļ┼¬ż╩┼∙▓┴övŽ®żŪ╔ĮĖĮż╣żļż╚ĪóMAC+źßźŌźĻĪ╩DRAMĪ╦ż“1ź╦źÕĪ╝źĒź¾ż╚żĘżŲĪóż│ż╬övŽ®ż“¾H┐¶╩┬š`ż╦╩┬ż┘żŲżżż»ĪŻ╝┬║▌ż╦żŽź╦źÕĪ╝źĒź¾ż“┐¶Ø▓ż½┐¶╝åż“▐kż─ż╬├▒░╠ż╦ż▐ż╚żßĪóżĮż╬źųźĒź├ź»ż“¾H┐¶╩┬š`ż╦╩┬ż┘żŲ╣įżŁĪó╦Nż“źŌźŪźļ▓Įż╣żļĪŻżĮżĘżŲĮj(lu©░)╬╠ż╬Š«żĄż╩MACż╚żżż”┤╦▄╣Įļ]ż¼GPUź┴ź├źūż╦żŽĮĖ└迥żņżŲżżżļż┐żßĪóNvidiaż╬GPUż¼AIź┴ź├źūż╚żĘżŲ╗╚ż’żņżŲżŁż┐ĪŻ
¾H┐¶ż╬MAC▒ķōQż╚źßźŌźĻż½żķż╩żļź╦źÕĪ╝źĒź¾źųźĒź├ź»ż“Ī󿥿ķż╦¾H┐¶╩┬ż┘żļż┐żßż╦żŽżŪżŁżļż└ż▒╚∙║┘▓ĮżĘżŲĄ═żß╣■żÓż└ż▒Ą═żß╣■ż▐ż╩ż▒żņżąĪó┐═┤ųż╬╦Nż╦żŽŲŽż½ż╩żżĪŻż│ż╬ż┐żß╚∙║┘▓ĮČ\Įčż¼AIź┴ź├źūż╦żŽØŁ═ūż╚ż╩żļĪŻ
GPUżõCPUż╬╚∙║┘▓ĮżŪżŽAMDżõQualcommż¼┐╩ż¾żŪż¬żĻĪóAMDżŽ7nmż╬GPUż“│½╚»żĘżŲżżżļĪŻż┐ż└żĘĪó▌xŠņż╦żŽĮążŲżżż╩żżż╚żżż”ĪŻ╣±ŲŌżŪźŪźŻĪ╝źūźķĪ╝ź╦ź¾ź░ż╬źšźņĪ╝źÓź’Ī╝ź»żŪżóżļChainerż“│½╚»żĘżŲżŁż┐źūźĻźšźĪĪ╝ź╔ź═ź├ź╚ź’Ī╝ź»ź╣╝ężŌAIź┴ź├źūż“2018ŃQ12ĘŅż╬ź╗ź▀ź│ź¾źĖźŃźčź¾żŪĖ½ż╗ż┐ż¼ĪóżĮż╬╗■żŽ12nmźūźĒź╗ź╣ż“╗╚ż├żŲżżż┐(╗▓╣═½@╬┴1)ĪŻTRIPLE-1żŽ╚∙║┘▓Įż╬└ĶŲ¼ż╦╬®ż┴Īó╣ŌĮĖ└čż╬AIź┴ź├źūż“ų`╗žż╣ż┐żß5nmż╬źŪźČźżź¾ż“┐╩żßżŲżŁż┐ĪŻż▐ż║żŽAIź│źóż“2019ŃQ9ĘŅż╦┤░└«żĄż╗źĄź¾źūźļĮą▓┘żĘĪóĖĮ║▀äh▓┴├µż└ĪŻ
╝ęŲŌżŪäh▓┴żĘż┐ż╚ż│żĒĪó16źėź├ź╚ż╬╗@┼┘żŪźįĪ╝ź»└Łē”1000 TFLOPSĪ╩1PFLOPSĪ╦żŪĪó┼┼╬üĖ·╬©żŽ10 FLOPS/WĪóAIź│źóµ£öüżŪ100Wż╚ż╩żļĪŻż┐ż└żĘ▒ķōQ╗@┼┘żŽ8źėź├ź╚żŪżŌ16źėź├ź╚żŪżŌ╩čż©żķżņżļżĶż”ż╦ż╩ż├żŲżżżļż╚żżż”ĪŻ
ż│ż╬±T▓╠ż¼┐āż╣żĶż”ż╦ĪóTRIPLE-1ż¼ż│ż└ż’żļż╬żŽĪó─ŃŠ├õJ┼┼╬ü▓Įż└ĪŻźŪĪ╝ź┐ź╗ź¾ź┐Ī╝żŪ│žØ{żĄż╗żļŠņ╣ńżŪżŌŠ├õJ┼┼╬üż╬─ŃżĄżŽĪóźŪĪ╝ź┐ź╗ź¾ź┐Ī╝ż╬ē”╬üż“æųż▓żļż│ż╚ż¼żŪżŁżļĪŻźŪĪ╝ź┐ź╗ź¾ź┐Ī╝żŪżŽ╗╚ż©żļ┼┼╬üż╦Ė┬─cż¼żóżļż┐żßĪóŠ├õJ┼┼╬üżóż┐żĻż╬└Łē”ż“æųż▓żļż│ż╚ż╦∙Z┐┤żĘżŲżŁż┐ĪŻ5nmż╚żżż”╚∙║┘▓ĮżŽĪó└Łē”żõĮĖ└č┼┘ż└ż▒żŪżŽż╩ż»ĪóŠ├õJ┼┼╬üż╬║’žō(f©┤)ż╦żŌĖ·▓╠ż¼żóżļĪŻ
ż┐ż└żĘĪó7nmż½żķ5nmżžż╚╚∙║┘▓Įż“┐╩żßżņżą┐╩żßżļż█ż╔Īóź╚źķź¾źĖź╣ź┐ż╬źąźķź─źŁż¼Įj(lu©░)żŁż»ż╩żĻĪó╩Ōé╬ż▐żĻżŽĄKż»ż╩żļĪŻżĮż│żŪĪó╩Ōé╬ż▐żĻż“▌ö┘ćż╣żļövŽ®ż“Ų│Ų■ż╣żļż│ż╚żŪźąźķź─źŁż“▌öĮ■żĘżŲżżżļż╚żżż”ĪŻź╚źķź¾źĖź╣ź┐ż╬źąźķź─źŁż“Å]┼┘ż╬Å]żżĪ”ęÆżżżŪ╩¼│õżĘ▌öĮ■żĘżŲżżż»ż╬ż└ż╚żżż”ĪŻż│żņż╦┤žżĘżŲżŽØŖß׿“Įą┤Ļ├µż└ż╚żĘżŲżżżļĪŻ
▐kż─ż╬ź│źóĪ╩MAC+źßźŌźĻĪ╦ż“╩┬š`ż╦ż║żķżĻż╚╩┬ż┘żļż’ż▒ż└ż¼ĪóżĮż╬╣įš`▒ķōQź│źóżŽżóżļĮj(lu©░)│žż╚Č”Ų▒żŪ│½╚»ĪóśO╝ężŪRTLĪ╩register transfer levelĪ╦ż“źūźĒź░źķźÓż╩ż¼żķĪóźĮźšź╚ź”ź©źóż╬▓■╬╔ż“▓├ż©żŲżŁż┐ż╚żĘżŲżżżļĪŻAIź│źóż╬Ū█ÅøŪ█└■źņźżźóź”ź╚żŽśO╝ężŪŠ}²Xż▒żŲż¬żĻĪó╚ŠŲ│öü└▀╝Ŗź©ź¾źĖź╦źóż¼¾Hżżż│ż╚ż“ż”ż½ż¼ż’ż╗żŲżżżļĪŻ╝ęµ^┐¶30ć@ż╬ŲŌ7│õż¼ź©ź¾źĖź╦źóż└ż╚żżż”ĪŻ
╝ĪżŽ│½╚»żĘż┐AIź│źóż“ż║żķżĻż╚╩┬ż┘żŲĪóźņź┴ź»źļźĄźżź║ż«żĻż«żĻż╬Įj(lu©░)żŁż╩ź┴ź├źū(25mmĪ▀32Łą)ż“└▀╝Ŗż╣żļż│ż╚ż└ĪŻSerDesż“▓żĘżŲ│░ŗż╚─╠┐«żĘĪóżĘż½żŌ│╚─ź└Łż“Ęeż┐ż╗żŲ╩┬š`└▄¶öżŪżŁżļżĶż”ż╦ż╣żļĪŻż│ż╬ż┐żßAIövŽ®ŗ╩¼ż╬ĀC└迎ż▐ż└└▀─ĻżĘżŲżżż╩żżĪŻŃQŲŌż╦żŽźŲĪ╝źūźóź”ź╚żĘż┐żżż╚┴TĄż╣■ż¾żŪżżżļĪŻŲ▒╗■╩┬╣į┼¬ż╦┐Õ╬õźĘź╣źŲźÓż“║╬├ōż╣żļż│ż╚ż╦ż╩żļż╚╗ūż’żņżļż¼Īó╩³ÕX└▀╝ŖżŌ│½╗Žż╣żļĪŻ
╗▓╣═½@╬┴
1. źūźĻźšźĪĪ╝ź╔ź═ź├ź╚ź’Ī╝ź»ź╣ĪóAI│žØ{ź┴ź├źūż“┤ķĖ½└ż (2018/12/18)

