└Łē”ż╚│╚─ź└Łż╬╣ŌżżMIMDźóĪ╝źŁźŲź»ź┴źŃż╬AIź┴ź├źūżŪ▒M╔ķż╣żļGraphcore
AIźūźĒź╗ź├źĄź┴ź├źūż½żķAIź│ź¾źįźÕĪ╝ź┐źĘź╣źŲźÓĪ╩┐▐1Ī╦ż▐żŪŠ}²Xż▒żļGraphcoreż¼2021ŃQż╦Ų■żĻŲ³╦▄żŪżŌīÖŲ░ż╦╬üż“Ų■żņżŲżżżļĪŻĄĪ│Ż│žØ{ż╦┼¼żĘż┐«Ć╩┬š`ĮĶ═²ż╬MIMDźóĪ╝źŁźŲź»ź┴źŃż“╗╚żżĪóAI└Łē”ż¼Č╦żßżŲ╣Ōżżż╬ż¼ØŖ─╣ż└ĪŻż╣żŪż╦▄f╣±─╠┐«ź¬ź┌źņĪ╝ź┐ż╬KTżŪź═ź├ź╚ź’Ī╝ź»Ė·╬©ż“æųż▓ĪóMicrosoft Azureź»źķź”ź╔æųżŪż╬░Õ┬ä▓ĶćĄ╩¼╬ÓŪ¦╝▒żŪ║Ū┐ĘGPUżĶżĻżŌ12Ū▄żŌ╣ŌÅ]ż╚żżż”╝┬└ėż“Ė½ż╗żŲżżżļĪŻ

┐▐1ĪĪIPUż“4Ė─┼ļ║▄żĘż┐AIź▄Ī╝ź╔ĪųIPU-GC200ĪóM2000ĪūĪĪż│ż╬1ĮŚż╬ź▄Ī╝ź╔ż╬└Łē”żŽ1PĪ╩ź┌ź┐Ī╦FLOPSĪĪĮąųZĪ¦Graphcore Corp.
▒č╣±ż╬źŽźżźŲź»Åžż╬▐kż─ĪóźųźĻź╣ź╚źļż╦╦▄╝ęż“Ęeż─GraphcoreżŽĪó└ż─cĘQ├Žż╦ź╗Ī╝źļź╣ź¬źšźŻź╣ż“ÅøżŁĪó│½╚»żĘż┐AIź▐źĘź¾ż╬╔ߥ┌ż╦┼žżßżŲżżżļĪŻ2016ŃQż╦└▀╬®żĄżņż┐żąż½żĻż╬ż│ż╬ź╣ź┐Ī╝ź╚źóź├źūżŽ7.1▓»ź╔źļż╬½@ČŌ─┤├Żż╦└«Ė∙żĘżŲżżżļż¼Īó┤ļČ╚▓┴├═żŽ27.7▓»ź╔źļż╦Ą┌żųż╚Ė½└čżŌżķżņżŲżżżļĪŻ
¾Hż»ż╬VCĪ╩Venture CapitalĪ╦żõGoogleĪóOpenAIĪóDeepMindż╩ż╔┤ļČ╚┼Ļ½@▓±╝ęż¼ż│ż│ż▐żŪÕX┐┤ż╦┼Ļ½@ż╣żļż╬żŽĪóGraphcoreż╬źŲź»ź╬źĒźĖĪ╝ż╦╣¹żņ╣■ż¾ż└ż½żķżŪżóżĒż”ĪŻ─╠┐«╩¼╠ŅżŪżŽĪóź═ź├ź╚ź’Ī╝ź»└Łē”ż╬║Ū┼¼▓Įż╦AIż“╗╚ż”ż│ż╚ż¼żĶż»╣įż’żņżŲżżżļż¼Īóź═ź├ź╚ź’Ī╝ź»ż╬ėX▌å╩č▓Įż½żķ└Łē”źčź┐Ī╝ź¾ż“╩¼└ŽżĘżŲż│żņż½żķ└Ķż╬└Łē”ż“═Į▒Rż╣żļĪŻ─╠┐«ź╚źķźšźŻź├ź»ż¼ĮĖ├µżĘżĮż”ż╦ż╩żņżąĄ£Øiż╦╗Īē¶żĘżŲŠŃ│▓ż“T┘ćżĘżŲż¬ż»ż│ż╚ż¼żŪżŁżļĪŻĖĮ║▀Īó║Ū└Ķ├╝żŪż½ż─╔ߥ┌żĘżŲżżżļNvidiaż╬GPUĪ╩V100Ī╦ż╚Š’ż╦╚µ│ėżĘżŲżżżļż¼Īóź═ź├ź╚ź’Ī╝ź»ż╬╩¼└ŽżŪżŽø]żżźņźżźŲź¾źĘżŪ╠¾260Ū▄Å]żżĪŻż▐ż┐ĪóMicrosoftż╬AIČ\Įčż“╗╚ż├żŲż╬░Õ┬ä▓Ķ楿╬▓“└ŽżŪGPUż╚╚µ│ėżĘż┐Šņ╣ńżŌ12Ū▄Å]ż½ż├ż┐ĪŻ
ż│ż╬AIź┴ź├źūĪųIPUĪ╩Intelligent Processing UnitĪ╦ĪūżŽ│╚─ź└Łż¼╣Ōż»ĪóIPUż“4Ė─┼ļ║▄żĘż┐┐▐1ż╬ź▄Ī╝ź╔Ī╩1PFLOPSż╬IPU-M2000Ī╦ż“4ĮŚ─_ż═żļIPU-POD16żŽĪó1ĮŚź▄Ī╝ź╔ż╬4Ū▄ż╬4PFLOPS└Łē”ż“╚»Ä¦żĘĪ󿥿ķż╦żĮżņż“4Ė──_ż═żļż╚żĄżķż╦4Ū▄ż╬16PFLOPSż╬└Łē”ż“Ęeż─źķź├ź»IPU-POD64ż╚ż╩żļĪŻż│żņż“4±ś└▄¶öż╣żļż╚żĄżķż╦4Ū▄ż╬64PĪ╩ź┌ź┐Ī╦FLOPSż╚ż╩żļĪ╩┐▐2Ī╦ĪŻ

┐▐2ĪĪIPUż“│╚─ź└▄¶öżĘżŲżŌ└Łē”żŽµ£ż»═Ņż┴ż╩żżĪĪĮąųZĪ¦Graphcore
ż│ż╬AIź┴ź├źūż╬║ŪĮjż╬ØŖ─╣żŽĪóż│żņż▐żŪż╬ź▐źļź┴ź│źóźóĪ╝źŁźŲź»ź┴źŃżŪżŽ╝┬ĖĮżŪżŁż╩ż½ż├ż┐MIMDĪ╩Multiple Instructions Multiple DataĪ╦ż“╗╚ż├żŲżżżļż│ż╚ż└ĪŻGPUżõCPUż╩ż╔ż╬ż│żņż▐żŪż╬źĘź╣źŲźÓżŪżŽSIMDĪ╩Single Instruction Multiple DataĪ╦źóĪ╝źŁźŲź»ź┴źŃż“ź┘Ī╝ź╣ż╦żĘżŲż¬żĻĪó╠┐╬ßź╗ź├ź╚ż¼╩Ż╗©ż╩ż╬żŪMIMDöĄ╝░ż“ż╚żļż│ż╚żŽžMżĘż½ż├ż┐ĪŻ
IPUźūźĒź╗ź├źĄżŽĪó┐═┤ųż╬╦Nż╦Įą═Ķżļż└ż▒ŖZżżźūźĒź╗ź├źĄż╚żĘżŲĪó«Ć╩┬š`ż╬MIMDźóĪ╝źŁźŲź»ź┴źŃż“║╬├ōżĘż┐ĪŻ┐═┤ųżŽŲ▒╗■ż╦╩Ż┐¶ż╬ż│ż╚ż“╣═ż©żļż½żķż└ż╚żżż”ĪŻżĮż│żŪĪóźūźĒź╗ź├źĄż╬ĄĪē”ż“ĄĪ│Ż│žØ{ż╬źūźĒź╗ź╣ż└ż▒ż╦Īó╠┐╬ßż“▒ķōQĪóŲ▒┤³ĪóźŪĪ╝ź┐Ė“┤╣ż╬įÆż─ż╦╣╩żļż│ż╚żŪĪóMIMDż“╗╚ż©żļżĶż”ż╦żĘż┐ĪŻ
ż▐ż┐ż│ż│żŪżŽ┐└Ęąż╬┼┴╚┬ż“╣═ż©żŲ╣ŌÅ]źßźŌźĻż╚ż╩żļSRAMż“║╬├ōżĘż┐ĪŻżĮżņżŌź┴ź├źūżóż┐żĻż╬źżź¾źūźĒź╗ź├źĄźßźŌźĻżŽ900MBżŌ┼ļ║▄żĘżŲżżżļĪŻ┐▐3ż╬żĶż”ż╦źßźŌźĻż╬├µż╦źūźĒź╗ź├źĄż╬ź│źóż¼ÜgżĻżążßżķżņż┐╣Įļ]ż“żĘżŲżżżļĪŻIPUż╦żŽŲ╚╬®żĘż┐ź│źóż¼1472Ė─ĮĖ└čżĘżŲż¬żĻĪó8832Ė─ż╬źūźĒź░źķźÓź╣źņź├ź╔ż¼żĮżņżŠżņŲ╚╬®ż╦Ų░ż»ĪŻTSMCż╬7nmźūźĒź╗ź╣żŪ×æļ]żĘĪóź┴ź├źūĀC└迎823mm2ĪŻIPUź┴ź├źūż╬Š├õJ┼┼╬üżŽ150WżŪĪóźęĪ╝ź╚źĘź¾ź»ż“└▀ż▒żŲżżżļż¼Īó╬õĄčżŽČ§╬õöĄ╝░ĪŻ
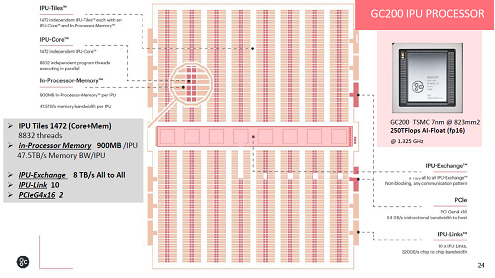
┐▐3ĪĪźżź¾źūźĒź╗ź├źĄźßźŌźĻĪ╩SRAMĪ╦ż“900MBĮĖ└čżĘĪó1472ź│źóż“ĮĖ└čżĘż┐IPUź┴ź├źūĪĪĮąųZĪ¦Graphcore
╩¼ÜgźßźŌźĻż“ŠW├ōżĘż┐MIMD╩┬š`▒ķōQżŪżŽĪóBSPĪ╩źąźļź»Ų▒┤³╩┬š`Ī╦źĮźšź╚ź”ź©źóż“╗╚ż├żŲĪó┐▐4ż╬żĶż”ż╦▒ķōQż╣żļĪŻż─ż▐żĻĪóIPUŲŌżŪżŽ▒ķōQżĘĪóŲ▒┤³ż“ż╚żļż╚źŪĪ╝ź┐ż╬ęÆżņżõ┐╩ż▀É║╣ńż¼źąźķźąźķż└ż¼ĪóźŪĪ╝ź┐ż“Ė“┤╣żĘĪ󿥿ķż╦▒ķōQż“┐╩żßżļĪŻ╝Īż╦żŌż”▐kż─ż╬IPUż╚żŌŲ▒┤³ż“ż╚żĻĪóźŪĪ╝ź┐Ė“┤╣Ī”▒ķōQż“╣įż”ĪŻ
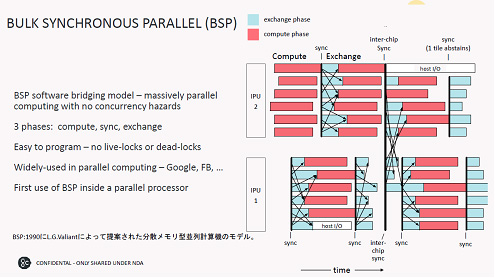
┐▐4ĪĪ▒ķōQĪ”Ų▒┤³Ī”źŪĪ╝ź┐Ė“┤╣ż╬3ż─ż╬╠┐╬ßżŪ«Ć╩┬š`ż“╝┬ĖĮĪĪIPUŲ▒╗╬żŌŲ▒┤³ż“ż╚żļĪĪĮąųZĪ¦Graphcore
ż│ż╬żĶż”ż╩öĄ╝░żŪ▒ķōQĪóŲ▒┤³ĪóźŪĪ╝ź┐Ė“┤╣ż“Ę½żĻ╩ųżĘżŲżżż»ż╚Ī󿥿ķż╦IPUż“╝{▓├żĘżŲżŌż╔ż│ż½żŪØŁż║Ų▒┤³ż“ż╚ż├żŲźŪĪ╝ź┐ĮĶ═²żĘżŲżżż»ż┐żßĪóIPUż“╝{▓├żĘżŲżŌ└Łē”żŽ═Ņż┴ż╩żżĪŻż│żņż¼┐▐2żŪ┐āżĘż┐ĪóIPUż“┼ļ║▄żĘż┐ź▄Ī╝ź╔ż“Įj╬╠ż╦╩┬š`│╚─źżŪżŁżļ═²Įyż└ĪŻ
IPU-M2000ź▄Ī╝ź╔ż╬Š├õJ┼┼╬üżŽ900Ī┴1100WĪ╩║YØŹĪ╦ż╚ĮjżŁżżż┐żßĪó├ō²ŗżŽźŪĪ╝ź┐ź╗ź¾ź┐Ī╝żõź»źķź”ź╔Ė■ż▒ż╦ż╩żļĪŻź▄Ī╝ź╔1ĮŚżŪ4Ė─ż╬IPUź┴ź├źūż“öUĖµż╣żļSoCżŽArmż╬Cortex-Aź│źóż╚FPGAż½żķż╩żļĪŻź▓Ī╝ź╚ź”ź©źżżŽIPUŲ▒╗╬ż“└▄¶öż╣żļż┐żßż╦╗╚ż”ĪŻż▐ż┐ź▄Ī╝ź╔ż╦żŽSSDżõDRAMźßźŌźĻżŌ┼ļ║▄żĘżŲż¬żĻĪóIPUź┴ź├źūżŽ150W/ź┴ź├źūż└ż¼Īóµ£öüżŪżŽ1kWØiĖÕż╦ż╩żļĪŻ
Graphcoreż╬äėż▀żŽź┴ź├źūż╚źŽĪ╝ź╔ź”ź©źóż╬│╚─ź└Łż└ż▒żŪżŽż╩żżĪŻźĮźšź╚ź”ź©źó│½╚»źŁź├ź╚żŌ├ō┴TżĘżŲż¬żĻĪóPytorchżõTensorFlowĪóOnnxż╩ż╔ĄĪ│Ż│žØ{źšźņĪ╝źÓź’Ī╝ź»ż╦żŌ×┤▒■żĘĪóGPUźķźżźųźķźĻż╬CUDAż╦┴Ļ┼÷ż╣żļżĶż”ż╩źĮźšź╚ź”ź©źóź╣ź┐ź├ź»ĪųPoplar-SDKĪūż“×óż©żŲżżżļĪŻ
„[─ĻĖ▄ĄężŽźŪĪ╝ź┐ź╗ź¾ź┐Ī╝ż“Ęeż─ĪóČŌ═╗ĪóHPCĪóźžźļź╣ź▒źóĪó│╬╬©┼²╝ŖĮĶ═²ż╩ż╔ż╬Č╚─cż╦ż╩żļĪŻĮjżŁż╩AIźŌźŪźļż╦żŌ×┤▒■żŪżŁżļż│ż╚ż¼IPUźĘź╣źŲźÓż╬äėż▀ż╚Ė└ż©żĮż”ż└ĪŻ

