7nmźūźĒź╗ź╣żŪ×æļ]żĘż┐ź”ź¦Ī╝źŽæä╠Žż╬ĄĮjż╩AIź┴ź├źū
ź”ź¦Ī╝źŽź╣ź▒Ī╝źļAIź┴ź├źū│½╚»ż╬Cerebras SystemsżŽĪóŗī2└ż┬Õż╬ź”ź¦Ī╝źŽź╣ź▒Ī╝źļAIź┴ź├źūż“│½╚»żĘż┐ĪŻ║ŪĮķż╬ź┴ź├źūż¼16nmźūźĒź╗ź╣żŪ×æļ]żĄżņżŲżżż┐ż¼Īó║ŻövżŽ7nmźūźĒź╗ź╣żŪ║ŅżķżņżŲż¬żĻĪó┴Ēź╚źķź¾źĖź╣ź┐┐¶żŽØiövż╬1├¹2000▓»ź╚źķź¾źĖź╣ź┐ż╦×┤żĘżŲ2.6├¹ź╚źķź¾źĖź╣ź┐ż╚ż█ż▄2Ū▄ż╦ż╩ż├żŲżżżļĪŻżĮż╬╩¼ź┴ź├źūæųż╬└Łē”ØŖ└ŁżŌ2Ū▄░╩æųż╦ż╩ż├żŲżżżļĪŻ
![┐▐1ĪĪ7nmźūźĒź╗ź╣żŪ×æļ]żĘż┐ź”ź¦Ī╝źŽź╣ź▒Ī╝źļAIź┴ź├źūĪĪĮąųZĪ¦Cerebras Systems](/archive/editorial/technology/img/TFC210428-01a.jpg)
┐▐1ĪĪ7nmźūźĒź╗ź╣żŪ×æļ]żĘż┐ź”ź¦Ī╝źŽź╣ź▒Ī╝źļAIź┴ź├źūĪĪĮąųZĪ¦Cerebras Systems
║Żövż╬AIźūźĒź╗ź├źĄWSE-2żŽĪóŗī1└ż┬Õż╬ź”ź¦Ī╝źŽź╣ź▒Ī╝źļAIźūźĒź╗ź├źĄĪ╩╗▓╣═½@╬┴1Īó2Ī╦ż╚Ų▒══Īó300mmź”ź¦Ī╝źŽ1ĮŚż½żķ1ź┴ź├źūż“ŲDżļż╚żżż”╩ĖÖC─╠żĻź”ź¦Ī╝źŽź╣ź▒Ī╝źļICżŪżóżļĪŻTSMCż╬7nmźūźĒź╗ź╣żŪ×æļ]żĄżņżŲż¬żĻĪóź│źó┐¶ĪóźßźŌźĻ═Ų╬╠ĪóźßźŌźĻ┬ė░Ķ╔²ĪóźšźĪźųźĻź├ź»┬ė░Ķ╔²ż╬ØŖ└ŁżŽµ£żŲŗī1└ż┬Õż╬żĮżņż╬2Ū▄░╩æųż╚ż╩ż├żŲżżżļĪŻ
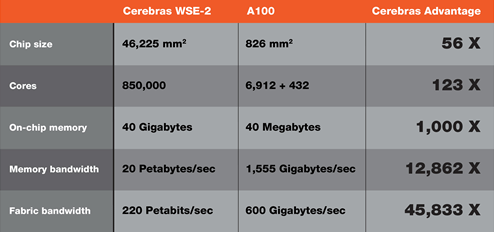
AIźūźĒź╗ź├źĄż“ĄĮjż╦│╚Įjż╣żļż│ż╚ż╦żĶż├żŲĪó╬Ńż©żą▒ķōQż╣żļż╬ż╦┐¶ź½ĘŅżŌż½ż½żļżĶż”ż╩ĄĮjż╩│žØ{źŌźŪźļż└ż╚Īóż│żņż▐żŪżŽĖ”ē|Ūvż¼╝┬├ō┼¬żŪżŽż╩żżż╚¬¤żßżŲżŁż┐ż¼Īóż│żņżŪżŌ┐¶ĮĄ┤ųĪóżóżļżżżŽ┐¶Ų³┤ųżŪ▓“ż▒żļżĶż”ż╦ż╩żļĪŻŗī1└ż┬Õż╬ź”ź¦Ī╝ź╣ź▒Ī╝źļź┴ź├źūż╚╚µż┘2Ū▄ż╬2.6├¹ź╚źķź¾źĖź╣ź┐żŽż│żņż▐żŪż╦ż╩żż║ŪĮjż╬╚ŠŲ│öüź┴ź├źūż╚ż╩żļĪŻĖĮ║▀ż╬║ŪĮjźņź┘źļż╬AIź┴ź├źūĪ╩GPUĪ╦żŽĪóNvidiaż╬A100ż¼ĮĖ└čż╣żļ542▓»ź╚źķź¾źĖź╣ź┐ż└ż¼Īóż│żņżĶżĻżŌ50Ū▄ĮjżŁżżĪŻżĮż╬└Łē”żŽĪ󿎿ļż½ż╦A100ż“╬┐ż░Ī╩┐▐2Ī╦ĪŻ
┐▐2ĪĪ║Ū╣Ō└Łē”ż╬GPUź┴ź├źūA100Ī╩Nvidia×æĪ╦ż╚╚µ│ėĪĪĮąųZĪ¦Cerebras Systems
ź┴ź├źūż¼ĮjżŁżż╩¼Īó▒ķōQż╣żļź│źó┐¶żõĪó▒ķōQ±T▓╠ż“▐k╗■┼¬ż╦°QżßżļźßźŌźĻż¼░Ą┼▌┼¬ż╦¾Hżżż┐żßĪó└Łē”żŽż▒ż┐░Ńżżż╦ĮjżŁżżĪŻź│źó┐¶żŽA100ż╬123Ū▄ĪóźßźŌźĻ═Ų╬╠żŽ1000Ū▄ĪóźßźŌźĻźąź¾ź╔╔²żŽ12,862Ū▄ĪóźšźĪźųźĻź├ź»źąź¾ź╔╔²żŽ45,833Ū▄ż╚ż▒ż┐░ŃżżżŪżóżļĪŻź┴ź├źūĀC└迎4╦³6225mm2ż╚żżż”ĄĮjż╩źĘźĻź│ź¾ż╬ōĮż╦ż╩ż├żŲżżżļĪŻż│ż╬ż┐żßĪó╔ĮĀCæųżŽź╣źŲź├źčż╬źņź┴ź»źļźĄźżź║ż╦╣ńż’ż╗ż┐æäō¦┼¬ż╩źčź┐Ī╝ź¾ż╚ż╩ż├żŲżżżļĪŻ
ź”ź¦Ī╝źŽ1ĮŚż╦Ż▒ź┴ź├źūż╚żżż”ź”ź¦Ī╝źŽź╣ź▒Ī╝źļICżŽĪó╝┬żŽ1980ŃQ┬Õż╦żŌżóż├ż┐ĪŻżĘż½żĘźĒźĖź├ź»ICżõźßźŌźĻICżŪżóż├ż┐ż┐żßĪóŪ█└■ż¼1╦▄żŪżŌ└┌żņżŲżżżļż╚╔į╬╔ēäż╚ż╩żĻĪóŪč┤■ż╣żļżĘż½ż╩ż½ż├ż┐ĪŻż│ż╬ż┐żß╩Ōé╬ż▐żĻżŽĖ┬żĻż╩ż»ź╝źĒż╦ŖZż½ż├ż┐ĪŻżĘż½żĘĪóź╦źÕĪ╝źķźļź═ź├ź╚ź’Ī╝ź»żŪ╔ĮĖĮżĄżņżļAIź┴ź├źūż└ż╚ĪóŪ█└■ż¼1╦▄żõ2╦▄└┌żņżŲżżżŲżŌ│žØ{ż╣żļē”╬üż╦żĄż█ż╔║╣żŽż╩żżĪŻż─ż▐żĻ╔į╬╔ēäż╦żŽż╩żķż╩żżż┐żßĪó╩Ōé╬ż▐żĻżŽżżż─żŌ100%ż╩ż╬żŪżóżļĪŻ
ź╦źÕĪ╝źķźļź═ź├ź╚ź’Ī╝ź»żŪżŽĪóšÅż╩└■Ę┴┬Õ┐¶▒ķōQż¼ØŁ═ūżŪĪóżĮżņż╦╣ńż’ż╗ż┐║Ū┼¼żŪĮ└Ųż╩ź│źóż╬└▀╝Ŗż¼ĄßżßżķżņżļĪŻ└■Ę┴┬Õ┐¶▒ķōQżŽĪó╣įš`▒ķōQżĮż╬żŌż╬ż└ż¼Īóź╦źÕĪ╝źķźļź═ź├ź╚ź’Ī╝ź»ØŖŃ~ż╬šÅżŪżóżļĪ╩SparseĪ╦ż╚żŽĪó╣įš`└«╩¼ż╬Įjŗ╩¼ż¼0Ī╩ź╝źĒĪ╦ż└ż╚żżż”┴T╠ŻżŪżóżļĪŻ0Ī▀┐¶ÖCżŽ0żŪżóżļż½żķĪóżĮż”żżż├ż┐ŗ╩¼ż╬²Xż▒ōQżŽŠ╩ŠSż╣żļż│ż╚żŪ▒ķōQź╣źįĪ╝ź╔ż“æųż▓żļż│ż╚ż¼AIź┴ź├źūż╬╣ŌÅ]▓Įż╦─_═ūż╦ż╩żļĪŻ
ź╦źÕĪ╝źķźļź═ź├ź╚ź’Ī╝ź»żŪżŽĪó▒ķōQż╚źßźŌźĻż“▓┐┼┘ż╚ż╩ż»Ę½żĻ╩ųż╣ĪŻż│ż╬ż┐żßĪó▒ķōQĪ╩MACĪ¦└čŽ┬▒ķōQĪ╦ż╚źßźŌźĻż“ź╗ź├ź╚ż╦żĘż┐źóĪ╝źŁźŲź»ź┴źŃżŽ╣ŌÅ]ż╦│žØ{ż╚┐õébż¼żŪżŁżļĪŻżĘż½żŌæä╠Žż“ź”ź¦Ī╝źŽźĄźżź║ż╦ų`▐kÜJ│╚Įjż╣żļż│ż╚żŪGPUż“┐¶Ø▓Īó┐¶╝å╩┬ż┘żļżĶżĻżŌ1ź┴ź├źūæųżŪ▒ķōQĪ”ĄŁ▓▒ż╣żļöĄż¼╗╚żżżõż╣ż»źĘź¾źūźļż╦ż╩żļż╚żżż”ĪŻ
ż│żņż▐żŪż╬▒ķōQżŪżŽĪóĮjżŁż╩┐õébźŌźŪźļż“╬╠╗ę▓ĮżĘżŲŠ«żĄż»ż╣żļż│ż╚ż╦żĶż├żŲĪó╝ŖōQż“Å]żßżŲżŁż┐ĪŻżĮż”ż╣żļż╚ĪóżŌż┴żĒż¾╗@┼┘ż¼ĄŠ└Ęż╦ż╩żļĪŻż│ż╬CS-2ż“╗╚ż├żŲ▒ķōQż╣żņżą╗@┼┘ż“ĄŠ└Ęż╦ż╣żļż│ż╚ż╩ż»ĪóżĘż½żŌÅ]┼┘ż“═Ņż╚żĄż║ż╦║čżÓĪŻź┴ź├źūæųż╦żóżļ85╦³ź│źóżŽź¬ź¾ź┴ź├źūźßź├źĘźÕżŪ└▄¶öżĄżņżŲż¬żĻĪó220PĪ╩ź┌ź┐Ī╦źėź├ź╚/╔├ż╚Å]żżĪŻżĘż½żŌ▒ķōQ±T▓╠ż“│╩Ū╝ż╣żļźßźŌźĻ═Ų╬╠żŽ40G źąźżź╚ż╬╣ŌÅ]SRAMż¼Ū█ÅøżĄżņżŲż¬żĻĪóźßźŌźĻż╬┬ė░Ķ╔²żŽ20Pźąźżź╚/╔├ż╚Č╦żßżŲ╣ŌÅ]żŪżóżļĪŻ
Ų▒╝꿎╚ŠŲ│öüź┴ź├źūż“└▀╝Ŗż╣żļż└ż▒żŪżŽż╩ż»Īóż│żņż“╝┬äóżĘż┐AIź│ź¾źįźÕĪ╝ź┐CS-2żŌ╚╬Ūõż╣żļĪŻź┴ź├źūż╬╬õĄčżõźčź├ź▒Ī╝źĖżŌśOżķ└▀╝ŖżĘżŲż¬żĻĪó┼┼Ė╗ż╬ČĪĄļżŽ“£═Ķż╚żŽ░ŃżżĪóĘQź│źóż╦Äņ─Šż╦ČĪĄļż╣żļż╚żżż”ĪŻ║ŪĮjż╬źĘź╣źŲźÓ┼┼╬üżŽ23kWż╦żŌż╩żļż┐żßĪó┐Õ╬õöĄ╝░ż“║╬├ōżĘżŲżżżļĪŻ
ź┴ź├źūż╬źĮźšź╚ź”ź©źóźūźķź├ź╚źšź®Ī╝źÓż╦żŽĪó▐k╚╠┼¬ż╩TensorFlowżõPyTorchż╩ż╔ż╬ĄĪ│Ż│žØ{ż╬źšźņĪ╝źÓź’Ī╝ź»ż¼┤▐ż▐żņżŲżżżļż┐żßĪóAIźŌźŪźļż╬Ė”ē|ŪvżŽ╗╚żż┤Ężņż┐ź─Ī╝źļż“╗╚ż├żŲCS-2ż╦źūźĒź░źķźÓżŪżŁżļĪŻ
żĄżķż╦ĪóŲ▒╝꿎ź╦źÕĪ╝źķźļź═ź├ź╚ź’Ī╝ź»ż“CS-2ż╬╝┬╣įźšźĪźżźļż╦śOŲ░┼¬ż╦╩č┤╣ż╣żļź│ź¾źčźżźķCGCĪ╩Cerbras Graph CompilerĪ╦żŌ─¾ČĪżĘżŲż¬żĻĪóĘQź╦źÕĪ╝źķźļź═ź├ź╚ź’Ī╝ź»ż╦╔wŃ~ż╬Ū█Åøż╚Ū█└■└▄¶öż“Ö┌└«ż╣żļĪŻż│ż╬±T▓╠Īóµu└▄ż╣żļźņźżźõĪ╝┤ųż╬─╠┐«ż╬źņźżźŲź¾źĘż“Š«żĄż»żŪżŁżļż╚żżż”ĪŻ
╗▓╣═½@╬┴
1. źŪźŻĪ╝źūźķĪ╝ź╦ź¾ź░│žØ{ż╦żŽź”ź¦Ī╝źŽæä╠Žż╬ĄĮjż╩ź┴ź├źūż¼ØŁ═ū (2019/08/27)
2. Cerebras╝ęĪ󟔟¦Ī╝źŽæä╠Žż╬AIź┴ź├źūż“╝┬äóżĘż┐ź│ź¾źįźÕĪ╝ź┐ż“╚»Ūõ (2019/12/20)

